(2020年1月時点)AtCoderの大学別レート分布
以前 Twitter に載せたやつです。
偏差値順にソートした大学別AtCoderレート分布最新版です(単位は%, 人) pic.twitter.com/Zq6Itqp8th
— saba (@saba_kpr) January 21, 2020
AtCoder アカウントの所属には任意の文字列を記入できるため、大学名の表記についてはこちら(google スプレッドシート )を参考にしています。所属を書いていない人もいるため、正確な分布ではないことに注意してください。
大学は偏差値順に並べました。左から高い順で、国公立と私立で分けています。また、偏差値は河合塾のデータを使用しました。偏差値が同じ場合の順序は指定していないため、「A大学よりB大学の方が偏差値高いでしょ」って思った場合はだいたい偏差値が同じ大学です。気にしないでください。
また、全ての大学を載せると長くなってしまうため、人数が10人以上の大学のみになっています。


人数グラフを見ると、基本的には高偏差値の大学ほど参加人数が多い傾向にあります。ところどころ飛び出ているのは、情報系の単科大学などです。
ていうか東大多すぎないですか??
以下人数表です。



(2019年末時点) AtCoder年代別レート分布
定期的に Twitter にあげていたやつですが、ブログを始めたのでこっちにも上げておきます。
1975年〜2006年生まれで集計しています。



コンテスト参加回数10回以上の人のみのデータも載せておきます。



2019年も終わりなので、6月初め、11月末、12月末に集計したそれぞれのデータを使って増加率を出してみます。
上から順に(生まれ年)(増加人数)(1日あたりの増加人数)です。


大学生の世代だと毎日1〜2人増えてるらしいです。すごいですね。年代別の増加率調べるの面白いので、これから毎月調べていこうと思います。
(2019年11月26日時点) AtCoder年代別レート分布
2019年11月26日時点のAtCoder年代別レート分布です。
1975年〜2006年生まれで集計しています。



2019年6月時点(前の記事)と比べると、1999年生まれと2000年生まれ(共におよそ大学1年生)が大幅に増加しています。大学に入ってから始めた層が多いと考えられます。また1996年と1998年に比べて1997年の増加率が低いのですが、就活のために始める層も多いということでしょうか(それか単に大学4年生だと忙しくて始める人が少ない?)。
コンテスト参加回数10回以上の人のみのデータも載せておきます。



(2019年6月7日時点) AtCoder年代別レート分布
2019年6月7日時点のAtCoder年代別レート分布です。
1980年〜2010年生まれで集計しています。



コンテスト参加回数10回以上の人のみのデータも載せておきます。



Rustに入門したのでとりあえずAtCoderで1万点分解いてみた
普段は Python しか書いてないんですけど、なんとなくで今回 Rust に入門してみました。 12 月 20 日に 公式チュートリアル を読み始めてその日のうちに 4 章までは読み終えることができ、21 日の 0 時から AtCoder の問題を解き始めました。
提出記録です。
今日中にRustで10000点分解きます(提出ぶら下げ用ツイート)
— saba (@saba_kpr) December 20, 2019
1万点解き終わったのが22時半なのでだいぶギリギリですね。
解いた問題の内訳は、
- A 問題:11 問
- B 問題:37 問
- C 問題:5 問
で、全部で 53 問です。
主に参考にしたサイト
- 公式チュートリアル
- 基本的な文法とかはここで最初にやりました。
- AtCoder に登録したら解くべき精選過去問 10 問を Rust で解いてみた
- 主に入力周りはここを参考にしました。(read 関数はそのままここに載っているものを使いました)
- 文字列操作 with Rust
- Python と違って文字列が地獄だったのでだいたいここを見ながらやりました。
- rust String &str の変換と、文字列 数値 の変換
- 競技プログラミングにおけるPythonとRustの対応関係まとめ
- set を使いたくなったのでそこだけここを参考にしました。
- Rustのイテレータの網羅的かつ大雑把な紹介
- Rustのデータ構造について調べた - std::vec::Vec
よく使ったやつ
ほぼ自分用のメモです。
みたいな入力を受け取りたいとき
let a: Vec<u32> = (0..n).map(|_| read()).collect();
二次元版(n行m列)
let mut a: Vec<Vec<i32>> = Vec::new(); a.resize(n, Vec::new()); for i in 0..n { a[i] = (0..m).map(|_| read()).collect(); }
Python と違って切り捨て除算は0方向に丸められる。
おわりに
疲れたのでしばらくはやりたくないですが、結構楽しかったので年明けたら他の言語でもやってみたいです。
こるぼーブログの挨拶文一覧を取得してみた
僕の友人がブログをやっているのですが、僕は彼の記事の挨拶文が好きです。そこで今回はその挨拶文を自動で取得してテキストファイルとして保存することにしました。
彼の挨拶は必ず「おはようございます。」から始まっていますが、この部分は別にいらないので省くとして、収集したいのは2文目です。 以前 AtCoder 上の情報を取得するのに Python を利用したスクレイピングを身に付けたので、今回はそれを利用します。
from urllib import request from bs4 import BeautifulSoup url = "https://zero-kpr.hatenablog.com/archive" html = request.urlopen(url) soup = BeautifulSoup(html, "html.parser") p = soup.find_all("p") greeting_list = [] # 挨拶文のリスト for tag in p: descri = tag.string if descri: # 文章を区切り、二文目のみにする text_list = str(descri).replace("\n", "").replace(" ", "").split("。") if len(text_list) > 1: greeting_list.append(text_list[1] + "。") # 邪魔な部分を消し、改行区切りで文字列にする greeting_text = "\n".join(greeting_list[:-3]) with open("zero_kpr_greeting.txt", mode="w") as f: f.write(greeting_text)
適当にぐちゃぐちゃやってたらコードが完成しました。

コードを実行することで無事取得し保存することができました。こうして一覧で見てみるとあんまり面白くないですね。
AtCoderのレートとRated Point Sumの散布図を作りました
タイトルの通りです。Rated Point Sum の他に AC 数でも作りました。
まずは AC 数です。そこそこ相関はありそうですが、青あたりから結構ばらつきがあります。相関係数は 0.66 でした。

次は Rated Point Sum です。AC 数と比べるだいぶ綺麗です。相関係数は 0.73 でした。やっぱり単純に解いた数よりは点数で比べた方が良いですね。AC 数は虚無埋めで稼げるので。

Rated Point Sum の方に「この点数分解けばその色になるのに十分」と思われる線を描いてみました。
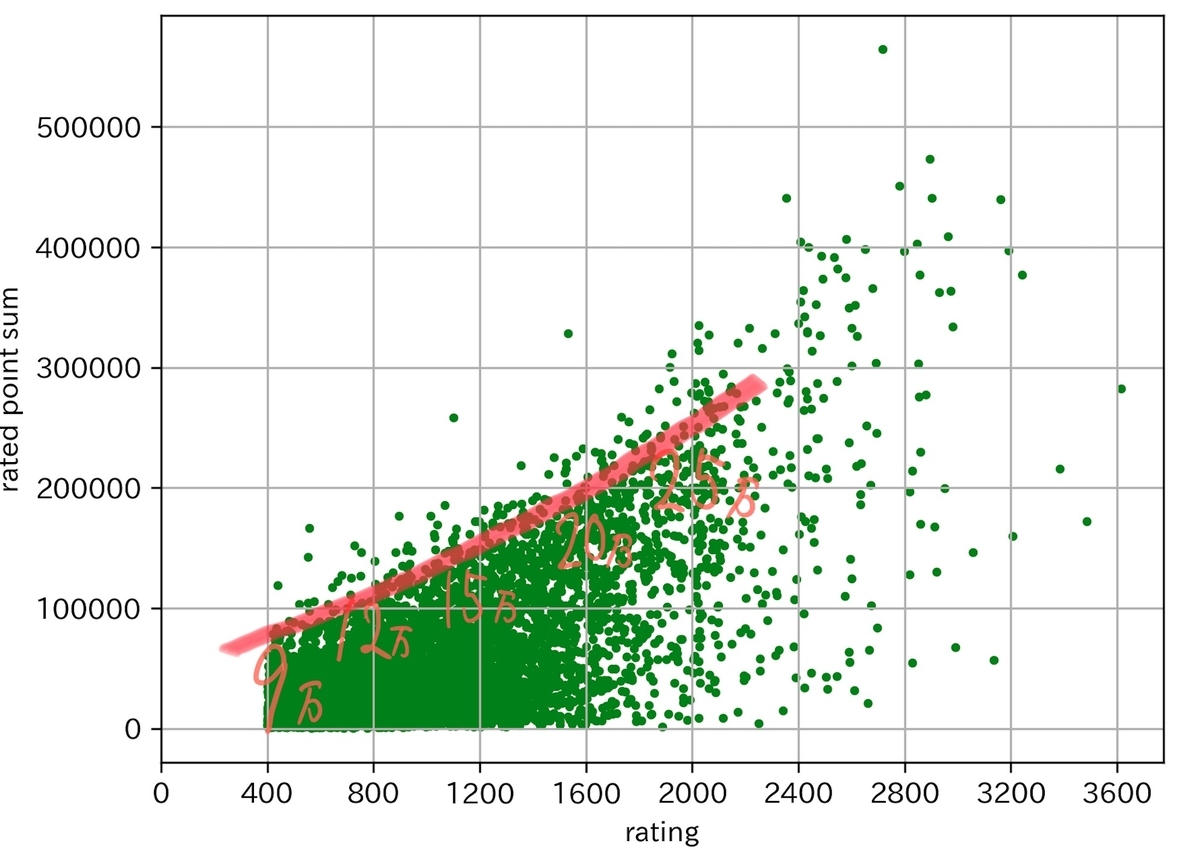 文字が見づらいですが、だいたい (合計点数 / 100) - 400 = レート くらいです。 (合計点数 / 100) はいわゆる精進グラフでの色なので、精進グラフではなりたい色より一つ上の色を目指して精進すれば十分です。(精進グラフに使用される値と Rated Point Sum は少し違いますが、目安なので)
文字が見づらいですが、だいたい (合計点数 / 100) - 400 = レート くらいです。 (合計点数 / 100) はいわゆる精進グラフでの色なので、精進グラフではなりたい色より一つ上の色を目指して精進すれば十分です。(精進グラフに使用される値と Rated Point Sum は少し違いますが、目安なので)